Google Gemma 2 veröffentlicht: Unterstützung für Forscher und Entwickler weltweit

Gemma 2: Globale KI-Innovation fördern
Einführung in Gemma 2
KI hat das Potenzial, einige der dringendsten Herausforderungen der Menschheit zu lösen – aber das kann nur geschehen, wenn jeder Zugang zu den nötigen Werkzeugen hat, um sie zu nutzen. Deshalb haben wir Anfang des Jahres Gemma vorgestellt, eine Familie leichter, hochmoderner offener Modelle, die mit der gleichen Forschung und Technologie gebaut wurden wie die Gemini-Modelle. Seitdem wurde die Gemma-Familie um CodeGemma, RecurrentGemma und PaliGemma erweitert, die jeweils einzigartige Funktionen für verschiedene KI-Aufgaben bieten. Diese Modelle sind durch Integrationen mit Partnern wie Hugging Face, NVIDIA und Ollama leicht zugänglich.
Weltweite Veröffentlichung von Gemma 2
Wir freuen uns, bekannt geben zu können, dass Gemma 2 nun offiziell für Forscher und Entwickler weltweit verfügbar ist. Gemma 2 wird in den Parametergrößen 9 Milliarden (9B) und 27 Milliarden (27B) angeboten und übertrifft die erste Generation in Leistung und Effizienz. Dank erheblicher Verbesserungen bei der Sicherheit bietet das 27B-Modell wettbewerbsfähige Alternativen zu Modellen, die mehr als doppelt so groß sind. Diese bemerkenswerte Leistung ist mit einem einzigen NVIDIA H100 Tensor Core GPU oder TPU-Host, wodurch die Bereitstellungskosten erheblich gesenkt werden.
Ein neuer Standard für Effizienz und Leistung von KI-Modellen
Neu gestaltete Architektur für optimale Leistung
Gemma 2 basiert auf einer neu gestalteten Architektur, die für außergewöhnliche Leistung und Inferenzeffizienz entwickelt wurde. Hier sind einige Hauptmerkmale, die es auszeichnen:
Übergroße Leistung
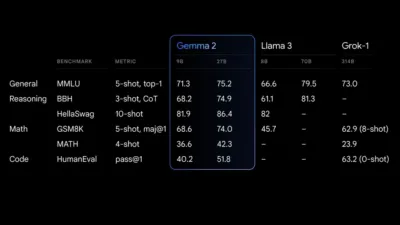
Das Modell 27B Gemma 2 bietet für seine Größe die beste Leistung seiner Klasse und stellt eine wettbewerbsfähige Alternative zu viel größeren Modellen dar. Auch das Modell 9B Gemma 2 ist herausragend und übertrifft andere offene Modelle seiner Kategorie, wie beispielsweise das Llama 3 8B. Eine detaillierte Aufschlüsselung seiner Leistung finden Sie im technischen Bericht.
Finale der Vorstellung von Gemma 2
Unübertroffene Effizienz und Kosteneinsparungen
Das Modell 27B Gemma 2 wurde für effiziente Inferenz entwickelt und läuft mit voller Präzision auf einem einzigen Google Cloud TPU-Host, NVIDIA A100 80 GB Tensor Core GPU oder NVIDIA H100 Tensor Core GPU. Diese Effizienz sorgt nicht nur für hohe Leistung, sondern senkt auch die Kosten erheblich, wodurch KI-Bereitstellungen zugänglicher und budgetfreundlicher werden.
Blitzschnelle Inferenz über die gesamte Hardware hinweg
Gemma 2 ist für unglaubliche Geschwindigkeiten auf verschiedenen Hardware-Setups optimiert, von leistungsstarken Gaming-Laptops und High-End-Desktops bis hin zu Cloud-basierten Umgebungen. Sie können Gemma 2 in Google AI Studio in voller Präzision erleben, die lokale Leistung mit der quantisierten Version mithilfe von Gemma.cpp auf Ihrer CPU freischalten oder es auf Ihrem Heimcomputer mit einer NVIDIA RTX oder GeForce RTX über Hugging Face Transformers ausführen.
Die Zukunft der KI mit Gemma 2
KI-Innovationen weltweit vorantreiben
Die Veröffentlichung von Gemma 2 stellt einen wichtigen Meilenstein dar, um Forschern und Entwicklern auf der ganzen Welt fortschrittliche KI-Technologien zugänglicher zu machen. Durch die Bereitstellung leistungsstarker Modelle, die effizient und kostengünstig sind, ermöglicht Gemma 2 Innovatoren, komplexe KI-Aufgaben ohne die Barrieren proprietärer Systeme anzugehen. Diese Demokratisierung von KI-Tools ist entscheidend, um die globale Zusammenarbeit zu fördern und den technologischen Fortschritt zu beschleunigen.
Engagement für Sicherheit und ethische KI
Neben seinen technischen Errungenschaften weist Gemma 2 auch wesentliche Sicherheitsverbesserungen auf, um einen ethischen Einsatz von KI zu gewährleisten. Diese Fortschritte unterstreichen unser Engagement für die Entwicklung von KI-Technologien, die nicht nur außergewöhnliche Leistungen erbringen, sondern auch hohe Sicherheits- und Verantwortungsstandards einhalten.
Schauen Sie sich die anderen KI-Neuigkeiten und Technologie-Events direkt hier in AIfuturize!