이 획기적인 기술은 종양을 식별할 수 있을 뿐만 아니라 사용자와 상호 작용하여 병리학 진단 및 연구를 위한 새로운 도구와 관점을 제공한다는 점은 주목할 가치가 있습니다.
PathChat: 다중 모드 병리학 탐지 AI 도우미
수년 동안 전산병리학은 병리학적 형태 데이터와 분자 검출 데이터를 분석하는 데 있어 상당한 진전을 이루었습니다. 병리학과 AI 및 컴퓨터 비전 기술의 교차로 형성된 이 틈새 연구 분야는 점차 의료 영상 분석 분야의 연구 핫스팟이 되고 있습니다.
전산병리학에는 이미지 처리와 AI 기술을 사용하여 AI 전산병리학 모델을 구축하는 작업이 포함됩니다. 이러한 모델은 조직병리학적 이미지를 획득하고 이러한 이미지의 형태학적 외관에 대한 예비 평가를 수행하여 자동화된 이미지 분석 기술을 통해 진단, 정량적 평가 및 의사 결정을 지원합니다.
현재 ChatGPT로 대표되는 생성 AI 기술의 폭발적인 성장으로 인해 다중 모드 대형 언어 모델(MLLM)이 전산 병리학 연구 및 병리학 임상 실습에 점점 더 많이 적용되고 있습니다. 그러나 고도로 전문화된 해부학적 병리학 하위 분야에서 병리학을 위한 일반 다중 모드 AI 보조 장치 구축에 대한 연구는 아직 초기 단계에 있습니다.
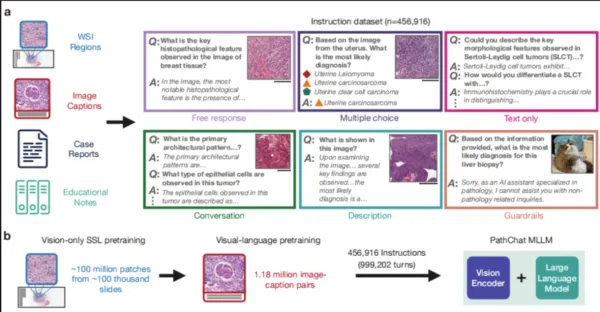
이 작업에서 연구팀은 특히 인간 병리학 연구를 위한 다중 모드 생성 AI 도우미인 PathChat을 설계했습니다. 그들은 100만 개 이상의 슬라이드에서 1억 개가 넘는 세포 조직 이미지 조각에 대한 자기 지도 학습을 통해 시스템을 사전 훈련했습니다. 이를 최첨단 순수 시각적 인코더인 UNI와 결합하여 시각적 및 자연어 입력을 모두 추론할 수 있는 MLLM을 생성했습니다. 450,000개 이상의 명령 데이터 포인트로 구성된 데이터 세트를 미세 조정한 후 PathChat이 구축되었습니다.
연구에 따르면 PathChat은 다중 모드 입력을 처리할 수 있을 뿐만 아니라 복잡한 병리 관련 문의에 정확하게 응답하여 거의 90% 사례의 생검 슬라이드에서 질병을 정확하게 식별할 수 있는 것으로 나타났습니다.
패스캐트
거의 90% 정확도로 GPT-4V를 능가
연구팀은 PathChat의 탐지 성능을 테스트하기 위해 PathChat을 오픈 소스 모델인 LLaVA, 생체의학 특화 LLaVA-Med, GPT-4V와 비교했습니다.
그들은 PathChat의 탐지 성능을 LLaVA, LLaVA-Med 및 GPT-4V와 비교하기 위해 다양한 기관 및 관행의 병리학적 사례를 분석하는 PathQABench 비교 실험을 설계했습니다.
결과는 임상적 맥락을 제공하지 않으면 PathChat의 진단 정확도가 LLaVA 1.5 및 LLaVA-Med보다 훨씬 더 높은 것으로 나타났습니다. 이미지만 평가할 때 PathChat은 모든 결합 벤치마크에서 78.1%의 정확도를 달성했습니다. 이는 LLaVA 1.5보다 52.4% 더 높고 LLaVA-Med보다 63.8% 더 높습니다.
임상적 맥락을 포함시키면 PathChat의 정확도는 89.5%로 더욱 높아졌습니다. 이는 LLaVA 1.5보다 39.0%, LLaVA-Med보다 60.9% 더 높습니다.
비교 실험을 통해 PathChat은 임상적 맥락에만 의존하기보다는 이미지의 시각적 특징만으로 상당한 예측 능력을 도출할 수 있음이 밝혀졌습니다. 일반적인 자연어를 통해 제공되는 비시각적 정보를 통합하여 조직학적 영상을 정확하게 진단하기 위한 다중 모드 정보를 효과적이고 유연하게 활용할 수 있습니다.
개방형 질문에 대한 각 모델의 응답 정확도를 객관적으로 평가하기 위해 연구팀은 7명의 병리학자를 모집하여 평가 패널을 구성했습니다. 260개의 개방형 질문에 대한 4가지 모델의 응답을 비교하여 모델 탐지의 정확성을 분석했습니다.
마지막으로, 7명의 전문가가 합의에 도달할 수 있는 개방형 질문에서 PathChat의 전체 정확도는 78.7%로 GPT-4V, LLaVA 1.5 및 LLaVA-Med보다 각각 26.4%, 48.9%, 48.1% 더 높았습니다. 전반적으로 PathChat은 다른 세 가지 모델에 비해 우수한 성능을 보여주었습니다.
연구원들은 PathChat이 병리학적 조직 이미지의 미묘한 형태학적 세부 사항을 분석하고 설명할 수 있다고 밝혔습니다. 이미지 입력 외에도 병리학 및 일반적인 생의학적 배경 지식이 필요한 질문에 답할 수 있으므로 병리학자와 연구자를 지원하는 유망한 도구입니다.
실험에서 PathChat의 탁월한 성능에도 불구하고 실제 적용에서는 여전히 몇 가지 문제에 직면해 있습니다. 여기에는 모델이 유효하지 않은 쿼리를 식별하고 잘못된 출력을 방지할 수 있는지 확인하고, 최신 의학 지식과의 동기화를 유지하고, PathChat의 훈련 데이터가 주로 최신 정보가 아닌 "과거의 과학적 합의"를 반영할 수 있는 과거 데이터에서 나온다는 사실을 다루는 것이 포함됩니다.
연구원들은 향후 연구를 통해 전체 기가픽셀 WSI 또는 여러 WSI 입력을 지원하고 정확한 계산 또는 개체 위치 파악과 같은 보다 많은 작업별 지원을 통합하는 등 PathChat의 기능을 더욱 향상시킬 수 있다고 밝혔습니다. 또한 PathChat을 디지털 슬라이드 뷰어 또는 전자 의료 기록과 통합하면 임상 실습에서의 실용성이 더욱 향상될 수 있습니다.
최근에는 다중 모드 생성 AI 모델인 PathChat 2가 출시되었습니다. 병리학 이미지와 텍스트를 추론하고 대화형 슬라이드 뷰어에서 여러 고해상도 이미지와 텍스트를 교대로 입력하여 각 상담 사례에 대해 보다 포괄적인 평가를 제공할 수 있습니다.
PathChat 1에 비해 감별진단 및 형태학적 설명 성능이 크게 향상되었습니다. 또한 지침 따르기, 개방형 질문 응답, 보고서 요약 등의 작업 기능도 향상되었습니다.