Google Gemma 2 Released: Empowering Researchers and Developers Worldwide

Gemma 2: Empowering Global AI Innovation
Introduction to Gemma 2
AI has the potential to solve some of humanity’s most pressing challenges — but this can only happen if everyone has access to the tools needed to harness it. That’s why, earlier this year, we introduced Gemma, a family of lightweight, state-of-the-art open models built using the same research and technology as the Gemini models. Since then, the Gemma family has expanded to include CodeGemma, RecurrentGemma, and PaliGemma, each offering unique capabilities for various AI tasks. These models are easily accessible through integrations with partners like Hugging Face, NVIDIA, and Ollama.
Global Release of Gemma 2
We are excited to announce that Gemma 2 is now officially available to researchers and developers worldwide. Offered in both 9 billion (9B) and 27 billion (27B) parameter sizes, Gemma 2 surpasses the first generation in both performance and efficiency. With significant safety advancements, the 27B model provides competitive alternatives to models more than twice its size. This remarkable performance is achievable on a single NVIDIA H100 Tensor Core GPU or TPU host, substantially lowering deployment costs.
A New Standard in AI Model Efficiency and Performance
Redesigned Architecture for Optimal Performance
Gemma 2 is built on a redesigned architecture engineered to deliver exceptional performance and inference efficiency. Here are some key features that make it stand out:
Outsized Performance
The 27B Gemma 2 model delivers best-in-class performance for its size, offering competitive alternatives to much larger models. The 9B Gemma 2 model also excels, outperforming other open models in its category, such as the Llama 3 8B. For a detailed breakdown of its performance, refer to the technical report.
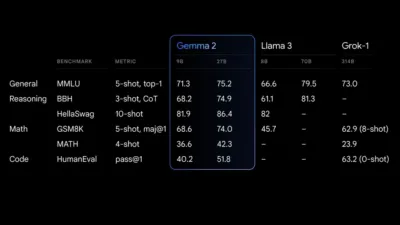
Gemma 2 performance final
Unmatched Efficiency and Cost Savings
Designed for efficient inference, the 27B Gemma 2 model operates at full precision on a single Google Cloud TPU host, NVIDIA A100 80GB Tensor Core GPU, or NVIDIA H100 Tensor Core GPU. This efficiency not only ensures high performance but also significantly reduces costs, making AI deployments more accessible and budget-friendly.
Blazing Fast Inference Across Hardware
Gemma 2 is optimized for incredible speed across various hardware setups, from powerful gaming laptops and high-end desktops to cloud-based environments. You can experience Gemma 2 at full precision in Google AI Studio, unlock local performance with the quantized version using Gemma.cpp on your CPU, or run it on your home computer with an NVIDIA RTX or GeForce RTX via Hugging Face Transformers.
Embracing the Future of AI with Gemma 2
Driving AI Innovation Globally
The release of Gemma 2 represents a significant milestone in making advanced AI technologies more accessible to researchers and developers around the globe. By providing high-performance models that are efficient and cost-effective, Gemma 2 empowers innovators to tackle complex AI tasks without the barrier of proprietary systems. This democratization of AI tools is crucial for fostering global collaboration and accelerating technological advancements.
Commitment to Safety and Ethical AI
Alongside its technical achievements, Gemma 2 incorporates substantial safety enhancements to ensure ethical AI deployment. These advancements underscore our commitment to building AI technologies that not only perform exceptionally but also adhere to high standards of safety and responsibility.
Check out the other AI news and technology events right here in AIfuturize!