It is worth noting that this breakthrough technology can not only identify tumors but also interact with users, providing new tools and perspectives for the diagnosis and research in pathology.
PathChat: Multimodal Pathology Detection AI Assistant
For many years, computational pathology has made significant progress in analyzing pathological morphology data and molecular detection data. This niche research field, formed by the intersection of pathology with AI and computer vision technologies, is gradually becoming a research hotspot in medical image analysis.
Computational pathology involves using image processing and AI technology to build AI computational pathology models. These models acquire histopathological images and conduct preliminary evaluations of the morphological appearance of these images to assist in diagnosis, quantitative assessment, and decision-making through automated image analysis techniques.
Currently, with the explosive growth of generative AI technologies represented by ChatGPT, multimodal large language models (MLLMs) are increasingly being applied in computational pathology research and clinical practice in pathology. However, in the highly specialized subfield of anatomical pathology, research on building general, multimodal AI assistants for pathology is still in its early stages.
In this work, the research team designed a multimodal generative AI assistant specifically for human pathology research—PathChat. They pre-trained the system through self-supervised learning on over 100 million cell tissue image fragments from more than 1 million slides. By combining this with a state-of-the-art pure visual encoder, UNI, they generated an MLLM capable of reasoning about both visual and natural language inputs. After fine-tuning on a dataset of more than 450,000 instruction data points, PathChat was constructed.
The research found that PathChat can not only handle multimodal inputs but also accurately respond to complex pathology-related inquiries, correctly identifying diseases from biopsy slides in nearly 90% of cases.
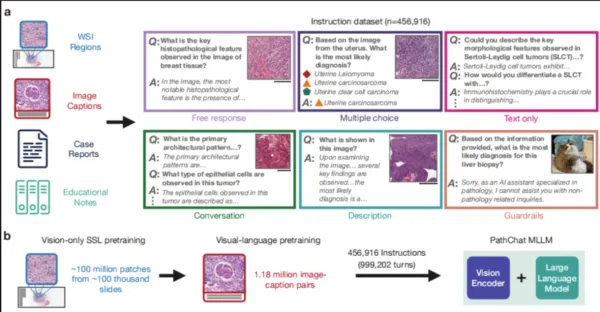
PathCaht
Surpassing GPT-4V with Nearly 90% Accuracy
To test the detection performance of PathChat, the research team compared PathChat with the open-source model LLaVA, the biomedical-specific LLaVA-Med, and GPT-4V.
They designed the PathQABench comparison experiment, analyzing pathological cases from different organs and practices to compare the detection performance of PathChat with LLaVA, LLaVA-Med, and GPT-4V.
The results showed that without providing clinical context, PathChat’s diagnostic accuracy was significantly higher than LLaVA 1.5 and LLaVA-Med. When evaluating images alone, PathChat achieved an accuracy of 78.1% across all combined benchmarks, which is 52.4% higher than LLaVA 1.5 and 63.8% higher than LLaVA-Med.
With the inclusion of clinical context, PathChat’s accuracy further increased to 89.5%, which is 39.0% higher than LLaVA 1.5 and 60.9% higher than LLaVA-Med.
The comparative experiment revealed that PathChat can derive substantial predictive capability from the visual features of images alone, rather than relying solely on clinical context. It can effectively and flexibly utilize multimodal information to accurately diagnose histological images by incorporating non-visual information provided through ordinary natural language.
To objectively evaluate the accuracy of each model’s responses to open-ended questions, the research team recruited seven pathologists to form an assessment panel. By comparing the responses of the four models to 260 open-ended questions, the accuracy of the model’s detections was analyzed.
Finally, on open-ended questions where the seven experts could reach a consensus, PathChat’s overall accuracy was 78.7%, which was 26.4%, 48.9%, and 48.1% higher than GPT-4V, LLaVA 1.5, and LLaVA-Med, respectively. Overall, PathChat demonstrated superior performance compared to the other three models.
Researchers indicated that PathChat can analyze and describe subtle morphological details in pathological tissue images. Besides image inputs, it can also answer questions requiring pathology and general biomedical background knowledge, making it a promising tool to assist pathologists and researchers.
Despite PathChat’s excellent performance in experiments, it still faces some challenges in practical applications. These include ensuring the model can identify invalid queries and avoid erroneous outputs, maintaining synchronization with the latest medical knowledge, and addressing the fact that PathChat’s training data mainly comes from historical data, which might reflect “past scientific consensus” rather than the latest information.
Researchers stated that future studies might further enhance PathChat’s capabilities, including supporting entire gigapixel WSI or multiple WSI inputs and integrating more task-specific support, such as precise counting or object localization. Additionally, integrating PathChat with digital slide viewers or electronic medical records might further improve its practicality in clinical practice.
Recently, the multimodal generative AI model PathChat 2 was released. It can reason over pathology images and text, accepting alternating inputs of multiple high-resolution images and text in an interactive slide viewer, thus providing more comprehensive evaluations for each consultation case.
Compared to PathChat 1, it has significantly improved performance in differential diagnosis and morphological description. It also has enhanced capabilities in tasks such as instruction following, open-ended question answering, and report summarization.