إطلاق Google Gemma 2: تمكين الباحثين والمطورين في جميع أنحاء العالم

جيما 2: تمكين الابتكار العالمي في مجال الذكاء الاصطناعي
مقدمة عن جيما 2
يتمتع الذكاء الاصطناعي بالقدرة على حل بعض التحديات الأكثر إلحاحًا التي تواجه البشرية - ولكن هذا لا يمكن أن يحدث إلا إذا تمكن الجميع من الوصول إلى الأدوات اللازمة لتسخيره. ولهذا السبب، قدمنا، في وقت سابق من هذا العام، مجموعة Gemma، وهي عائلة من النماذج المفتوحة خفيفة الوزن والمتطورة والتي تم تصميمها باستخدام نفس البحث والتكنولوجيا مثل نماذج الجوزاء. منذ ذلك الحين، توسعت عائلة Gemma لتشمل CodeGemma وRecurrentGemma وPaliGemma، حيث يقدم كل منها إمكانات فريدة لمختلف مهام الذكاء الاصطناعي. يمكن الوصول بسهولة إلى هذه النماذج من خلال عمليات التكامل مع شركاء مثل Hugging Face وNVIDIA وOllama.
الإصدار العالمي لجيما 2
يسعدنا أن نعلن أن Gemma 2 أصبحت الآن متاحة رسميًا للباحثين والمطورين في جميع أنحاء العالم. يتم تقديم Gemma 2 بأحجام معلمات تبلغ 9 مليارات (9B) و27 مليار (27B)، وتتفوق على الجيل الأول من حيث الأداء والكفاءة. بفضل التطورات الكبيرة في مجال السلامة، يوفر الطراز 27B بدائل تنافسية للطرز التي يزيد حجمها عن ضعف حجمها. هذا الأداء الرائع يمكن تحقيقه على واحد وحدة معالجة الرسوميات NVIDIA H100 Tensor Core أو مضيف TPU، مما يخفض تكاليف النشر بشكل كبير.
معيار جديد في كفاءة وأداء نموذج الذكاء الاصطناعي
بنية مُعاد تصميمها لتحقيق الأداء الأمثل
تم تصميم Gemma 2 بناءً على بنية مُعاد تصميمها لتوفير أداء استثنائي وكفاءة استدلالية. فيما يلي بعض الميزات الرئيسية التي تجعله متميزًا:
أداء ضخم
يقدم طراز 27B Gemma 2 أفضل أداء في فئته بالنسبة لحجمه، مما يوفر بدائل تنافسية للنماذج الأكبر حجمًا. كما يتفوق طراز 9B Gemma 2، حيث يتفوق على الموديلات المفتوحة الأخرى في فئته، مثل Llama 3 8B. للحصول على تفاصيل مفصلة عن أدائها، راجع التقرير الفني.
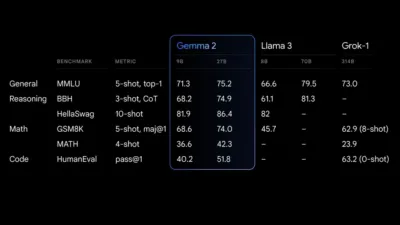
جيما 2 الأداء النهائي
كفاءة لا مثيل لها وتوفير في التكاليف
تم تصميم طراز 27B Gemma 2 للاستدلال الفعال، ويعمل بدقة كاملة على مضيف Google Cloud TPU واحد، أو وحدة معالجة الرسومات NVIDIA A100 Tensor Core بسعة 80 جيجابايت، أو وحدة معالجة الرسومات NVIDIA H100 Tensor Core. لا تضمن هذه الكفاءة الأداء العالي فحسب، بل تقلل أيضًا من التكاليف بشكل كبير، مما يجعل عمليات نشر الذكاء الاصطناعي أكثر سهولة ومناسبة للميزانية.
استنتاج سريع للغاية عبر الأجهزة
تم تحسين Gemma 2 للحصول على سرعة مذهلة عبر إعدادات الأجهزة المختلفة، بدءًا من أجهزة الكمبيوتر المحمولة القوية المخصصة للألعاب وأجهزة الكمبيوتر المكتبية المتطورة وحتى البيئات السحابية. يمكنك تجربة Gemma 2 بدقة كاملة في Google AI Studio، أو إطلاق العنان للأداء المحلي باستخدام الإصدار الكمي باستخدام Gemma.cpp على وحدة المعالجة المركزية الخاصة بك، أو تشغيله على جهاز الكمبيوتر المنزلي الخاص بك باستخدام NVIDIA RTX أو GeForce RTX عبر Hugging Face Transformers.
احتضان مستقبل الذكاء الاصطناعي مع جيما 2
قيادة ابتكارات الذكاء الاصطناعي على مستوى العالم
يمثل إصدار Gemma 2 علامة بارزة في جعل تقنيات الذكاء الاصطناعي المتقدمة في متناول الباحثين والمطورين في جميع أنحاء العالم. من خلال توفير نماذج عالية الأداء تتسم بالكفاءة والفعالية من حيث التكلفة، تعمل Gemma 2 على تمكين المبتكرين من معالجة مهام الذكاء الاصطناعي المعقدة دون حاجز الأنظمة الخاصة. إن إضفاء الطابع الديمقراطي على أدوات الذكاء الاصطناعي أمر بالغ الأهمية لتعزيز التعاون العالمي وتسريع التقدم التكنولوجي.
الالتزام بالسلامة والذكاء الاصطناعي الأخلاقي
إلى جانب إنجازاتها التقنية، تتضمن Gemma 2 تحسينات جوهرية للسلامة لضمان النشر الأخلاقي للذكاء الاصطناعي. تؤكد هذه التطورات التزامنا ببناء تقنيات الذكاء الاصطناعي التي لا تقدم أداءً استثنائيًا فحسب، بل تلتزم أيضًا بمعايير عالية من السلامة والمسؤولية.
تحقق من الآخر أخبار الذكاء الاصطناعي وأحداث التكنولوجيا الصحيحة هنا في AIfuturize!