Google Gemma 2 Dirilis: Memberdayakan Peneliti dan Pengembang di Seluruh Dunia

Gemma 2: Memberdayakan Inovasi AI Global
Pengantar Gemma 2
AI mempunyai potensi untuk memecahkan beberapa tantangan paling mendesak yang dihadapi umat manusia — namun hal ini hanya dapat terjadi jika setiap orang memiliki akses terhadap alat yang diperlukan untuk memanfaatkannya. Itu sebabnya, awal tahun ini, kami memperkenalkan Gemma, rangkaian model terbuka yang ringan dan canggih yang dibuat menggunakan penelitian dan teknologi yang sama dengan Gemma. Model Gemini. Sejak itu, keluarga Gemma telah berkembang hingga mencakup CodeGemma, RecurrentGemma, dan PaliGemma, masing-masing menawarkan kemampuan unik untuk berbagai tugas AI. Model-model ini mudah diakses melalui integrasi dengan mitra seperti Hugging Face, NVIDIA, dan Ollama.
Rilis Global Gemma 2
Kami sangat gembira mengumumkan bahwa Gemma 2 kini secara resmi tersedia bagi para peneliti dan pengembang di seluruh dunia. Ditawarkan dalam ukuran parameter 9 miliar (9 miliar) dan 27 miliar (27 miliar), Gemma 2 melampaui generasi pertama dalam hal kinerja dan efisiensi. Dengan kemajuan keselamatan yang signifikan, model 27B memberikan alternatif kompetitif dibandingkan model yang ukurannya lebih dari dua kali lipat. Performa luar biasa ini dapat dicapai dengan satu single GPU Inti Tensor NVIDIA H100 atau host TPU, yang secara signifikan menurunkan biaya penerapan.
Standar Baru dalam Efisiensi dan Kinerja Model AI
Arsitektur yang Didesain Ulang untuk Kinerja Optimal
Gemma 2 dibangun berdasarkan arsitektur yang didesain ulang untuk memberikan kinerja luar biasa dan efisiensi inferensi. Berikut beberapa fitur utama yang membuatnya menonjol:
Performa Luar Biasa
Model 27B Gemma 2 memberikan kinerja terbaik di kelasnya untuk ukurannya, menawarkan alternatif kompetitif dibandingkan model yang jauh lebih besar. Model 9B Gemma 2 juga unggul, mengungguli model terbuka lain di kategorinya, seperti Llama 3 8B. Untuk rincian kinerjanya, lihat laporan teknis.
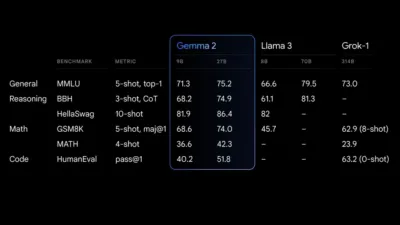
Pertunjukan terakhir Gemma 2
Efisiensi dan Penghematan Biaya yang Tak Tertandingi
Dirancang untuk inferensi yang efisien, model 27B Gemma 2 beroperasi dengan presisi penuh pada satu host Google Cloud TPU, GPU Tensor Core NVIDIA A100 80 GB, atau GPU Tensor Core NVIDIA H100. Efisiensi ini tidak hanya memastikan kinerja tinggi tetapi juga mengurangi biaya secara signifikan, menjadikan penerapan AI lebih mudah diakses dan ramah anggaran.
Inferensi Sangat Cepat di Seluruh Perangkat Keras
Gemma 2 dioptimalkan untuk kecepatan luar biasa di berbagai pengaturan perangkat keras, mulai dari laptop gaming yang kuat dan desktop kelas atas hingga lingkungan berbasis cloud. Anda dapat merasakan Gemma 2 dengan presisi penuh di Google AI Studio, membuka performa lokal dengan versi terkuantisasi menggunakan Gemma.cpp di CPU Anda, atau menjalankannya di komputer rumah Anda dengan NVIDIA RTX atau GeForce RTX melalui Hugging Face Transformers.
Merangkul Masa Depan AI dengan Gemma 2
Mendorong Inovasi AI Secara Global
Peluncuran Gemma 2 mewakili tonggak penting dalam menjadikan teknologi AI canggih lebih mudah diakses oleh para peneliti dan pengembang di seluruh dunia. Dengan menyediakan model berkinerja tinggi yang efisien dan hemat biaya, Gemma 2 memberdayakan inovator untuk menangani tugas-tugas AI yang kompleks tanpa hambatan sistem kepemilikan. Demokratisasi alat AI ini sangat penting untuk mendorong kolaborasi global dan mempercepat kemajuan teknologi.
Komitmen terhadap Keamanan dan Etis AI
Selain pencapaian teknisnya, Gemma 2 juga menyertakan peningkatan keamanan yang substansial untuk memastikan penerapan AI yang etis. Kemajuan ini menggarisbawahi komitmen kami untuk membangun teknologi AI yang tidak hanya berkinerja luar biasa namun juga mematuhi standar keselamatan dan tanggung jawab yang tinggi.
Lihat yang lain berita AI dan peristiwa teknologi dengan benar di sini di AIfuturize!