Google Gemma 2 リリース: 世界中の研究者と開発者を支援

Gemma 2: グローバルな AI イノベーションの推進
ジェマ2の紹介
AIは人類の最も差し迫った課題のいくつかを解決する可能性を秘めていますが、これは誰もがAIを活用するために必要なツールにアクセスできる場合にのみ実現します。そのため、今年初めに、私たちは軽量で最先端のオープンモデルファミリーであるGemmaを導入しました。これは、 ジェミニモデルそれ以来、Gemma ファミリーは CodeGemma、RecurrentGemma、PaliGemma を含むように拡張され、それぞれがさまざまな AI タスクに独自の機能を提供しています。これらのモデルは、Hugging Face、NVIDIA、Ollama などのパートナーとの統合を通じて簡単にアクセスできます。
ジェマ2の世界公開
Gemma 2が世界中の研究者や開発者に正式に提供されることをお知らせします。90億(9B)と270億(27B)のパラメータサイズで提供されるGemma 2は、パフォーマンスと効率の両方で第1世代を上回ります。安全性が大幅に向上した27Bモデルは、その2倍以上のサイズのモデルに匹敵する競争力のある代替品を提供します。この驚くべきパフォーマンスは、単一のマシンで達成できます。 NVIDIA H100 テンソルコア GPU または TPU ホストを使用することで、導入コストを大幅に削減できます。
AIモデルの効率性とパフォーマンスにおける新たな基準
最適なパフォーマンスのために再設計されたアーキテクチャ
Gemma 2 は、優れたパフォーマンスと推論効率を実現するように設計された再設計されたアーキテクチャ上に構築されています。Gemma 2 の主な特徴は次のとおりです。
並外れたパフォーマンス
27B Gemma 2 モデルは、そのサイズではクラス最高のパフォーマンスを発揮し、はるかに大型のモデルに匹敵する競争力のある選択肢を提供します。9B Gemma 2 モデルも優れており、Llama 3 8B など、同じカテゴリの他のオープン モデルよりも優れています。パフォーマンスの詳細な内訳については、技術レポートを参照してください。
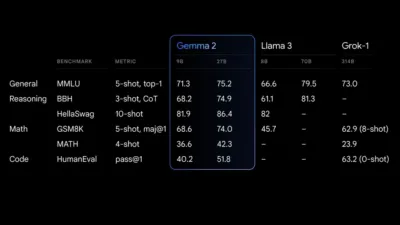
ジェマ2 パフォーマンスファイナル
比類のない効率性とコスト削減
効率的な推論のために設計された 27B Gemma 2 モデルは、単一の Google Cloud TPU ホスト、NVIDIA A100 80GB Tensor Core GPU、または NVIDIA H100 Tensor Core GPU で完全な精度で動作します。この効率性により、高いパフォーマンスが保証されるだけでなく、コストも大幅に削減され、AI の導入がよりアクセスしやすく、予算に優しいものになります。
ハードウェア間の超高速推論
Gemma 2 は、強力なゲーミング ノート PC やハイエンド デスクトップからクラウドベースの環境まで、さまざまなハードウェア設定で驚異的な速度を実現するように最適化されています。Google AI Studio で Gemma 2 をフル精度で体験したり、CPU で Gemma.cpp を使用して量子化バージョンでローカル パフォーマンスを解き放ったり、Hugging Face Transformers を介して NVIDIA RTX または GeForce RTX を搭載した自宅のコンピューターで実行したりできます。
Gemma 2 で AI の未来を受け入れる
AIイノベーションを世界規模で推進
Gemma 2 のリリースは、世界中の研究者や開発者が高度な AI テクノロジーをより利用しやすくするための重要なマイルストーンです。効率的でコスト効率の高い高性能モデルを提供することで、Gemma 2 はイノベーターが独自システムの障壁なしに複雑な AI タスクに取り組むことを可能にします。AI ツールのこの民主化は、グローバルなコラボレーションを促進し、テクノロジーの進歩を加速するために不可欠です。
安全性と倫理的なAIへの取り組み
Gemma 2 は、技術的な成果に加え、倫理的な AI 展開を保証するために大幅な安全性強化も実現しています。これらの進歩は、優れたパフォーマンスを発揮するだけでなく、安全性と責任の高度な基準に準拠する AI テクノロジーを構築するという当社の取り組みを強調するものです。
他のものもチェック AIニュース そしてテクノロジーイベント AIfuturizeでは!