この画期的な技術は腫瘍を特定できるだけでなく、ユーザーと対話して、病理学の診断と研究に新たなツールと視点を提供できる点も注目に値します。
PathChat: マルチモーダル病理検出 AI アシスタント
計算病理学は長年にわたり、病理形態データと分子検出データの解析において大きな進歩を遂げてきました。病理学と AI およびコンピューター ビジョン技術の融合によって形成されたこのニッチな研究分野は、徐々に医療画像解析の研究のホットスポットになりつつあります。
計算病理学では、画像処理と AI 技術を使用して AI 計算病理学モデルを構築します。これらのモデルは、組織病理学的画像を取得し、これらの画像の形態学的外観の予備評価を実施して、自動画像分析技術による診断、定量的評価、意思決定を支援します。
現在、ChatGPTに代表される生成AI技術の爆発的な成長により、マルチモーダル大規模言語モデル(MLLM)は、計算病理学研究や病理学の臨床実践にますます応用されています。しかし、解剖病理学という高度に専門化されたサブフィールドでは、病理学用の汎用的なマルチモーダルAIアシスタントの構築に関する研究はまだ初期段階にあります。
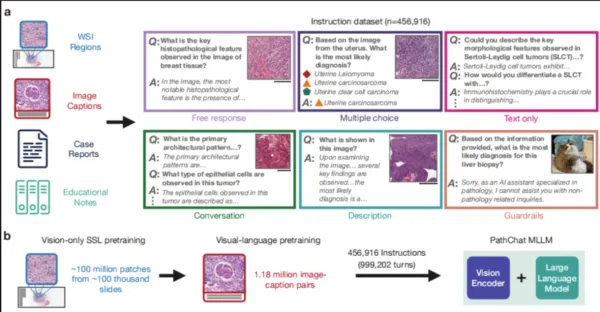
この研究で、研究チームは、特に人間の病理学研究向けのマルチモーダル生成 AI アシスタントである PathChat を設計しました。100 万枚以上のスライドから 1 億枚以上の細胞組織画像断片を使用して、自己教師あり学習によってシステムを事前トレーニングしました。これを最先端の純粋なビジュアル エンコーダーである UNI と組み合わせることで、視覚入力と自然言語入力の両方を推論できる MLLM を生成しました。45 万を超える指示データ ポイントのデータセットを微調整した後、PathChat が構築されました。
調査の結果、PathChat はマルチモーダル入力を処理できるだけでなく、複雑な病理関連の問い合わせにも正確に応答し、約 90% の症例で生検スライドから病気を正確に特定できることがわかりました。
パスカート
90% に近い精度で GPT-4V を上回る
PathChat の検出性能をテストするために、研究チームは PathChat をオープンソース モデル LLaVA、生物医学特有の LLaVA-Med、GPT-4V と比較しました。
彼らは、PathQABench 比較実験を設計し、さまざまな臓器や診療からの病理学的症例を分析して、PathChat の検出パフォーマンスを LLaVA、LLaVA-Med、GPT-4V と比較しました。
結果は、臨床コンテキストを提供しない場合、PathChat の診断精度が LLaVA 1.5 および LLaVA-Med よりも大幅に高いことを示しました。画像のみを評価した場合、PathChat はすべての複合ベンチマークで 78.1% の精度を達成しました。これは、LLaVA 1.5 よりも 52.4%、LLaVA-Med よりも 63.8% 高い値です。
臨床コンテキストが組み込まれると、PathChat の精度はさらに 89.5% に向上し、LLaVA 1.5 よりも 39.0%、LLaVA-Med よりも 60.9% 高くなりました。
比較実験により、PathChat は臨床コンテキストだけに頼るのではなく、画像の視覚的特徴のみからかなりの予測能力を引き出せることが明らかになりました。PathChat は、通常の自然言語を通じて提供される非視覚的情報を組み込むことで、マルチモーダル情報を効果的かつ柔軟に活用し、組織学的画像を正確に診断できます。
自由形式の質問に対する各モデルの回答の正確さを客観的に評価するために、研究チームは 7 人の病理学者を募集して評価パネルを構成しました。260 の自由形式の質問に対する 4 つのモデルの回答を比較することで、モデルの検出の正確さが分析されました。
最後に、7 人の専門家が合意に達することができた自由回答形式の質問では、PathChat の全体的な精度は 78.7% で、GPT-4V、LLaVA 1.5、LLaVA-Med よりもそれぞれ 26.4%、48.9%、48.1% 高くなりました。全体的に、PathChat は他の 3 つのモデルと比較して優れたパフォーマンスを示しました。
研究者らは、PathChat が病理組織画像の微妙な形態の詳細を分析して説明できることを指摘しました。画像入力のほかに、病理学や一般的な生物医学的背景知識を必要とする質問にも答えることができるため、病理学者や研究者を支援する有望なツールとなっています。
PathChat は実験では優れたパフォーマンスを発揮しましたが、実際のアプリケーションではまだいくつかの課題に直面しています。これには、モデルが無効なクエリを識別して誤った出力を回避できることを保証すること、最新の医学知識との同期を維持すること、PathChat のトレーニング データが主に過去のデータから取得され、最新の情報ではなく「過去の科学的コンセンサス」を反映している可能性があるという事実に対処することが含まれます。
研究者らは、今後の研究により、ギガピクセル WSI 全体または複数の WSI 入力のサポートや、正確なカウントやオブジェクトの特定など、よりタスク固有のサポートの統合など、PathChat の機能がさらに強化される可能性があると述べています。さらに、PathChat をデジタル スライド ビューアーや電子医療記録と統合することで、臨床現場での実用性がさらに向上する可能性があります。
最近、マルチモーダル生成 AI モデル PathChat 2 がリリースされました。病理画像とテキストを推論し、インタラクティブなスライド ビューアーで複数の高解像度画像とテキストの交互入力を受け入れることで、各診察ケースに対してより包括的な評価を提供します。
PathChat 1 と比較すると、鑑別診断と形態学的説明のパフォーマンスが大幅に向上しました。また、指示の遵守、自由形式の質問への回答、レポートの要約などのタスクの機能も強化されています。