Lançado Google Gemma 2: capacitando pesquisadores e desenvolvedores em todo o mundo

Gemma 2: Capacitando a inovação global em IA
Introdução à Gema 2
A IA tem potencial para resolver alguns dos desafios mais prementes da humanidade — mas isso só poderá acontecer se todos tiverem acesso às ferramentas necessárias para aproveitá-la. É por isso que, no início deste ano, apresentamos o Gemma, uma família de modelos abertos leves e de última geração, construídos usando a mesma pesquisa e tecnologia que o Modelos Gêmeos. Desde então, a família Gemma se expandiu para incluir CodeGemma, RecurrentGemma e PaliGemma, cada um oferecendo recursos exclusivos para diversas tarefas de IA. Esses modelos são facilmente acessíveis por meio de integrações com parceiros como Hugging Face, NVIDIA e Ollama.
Lançamento Global de Gemma 2
Temos o prazer de anunciar que Gemma 2 está agora oficialmente disponível para pesquisadores e desenvolvedores em todo o mundo. Oferecido em tamanhos de parâmetros de 9 bilhões (9B) e 27 bilhões (27B), o Gemma 2 supera a primeira geração em desempenho e eficiência. Com avanços significativos em segurança, o modelo 27B oferece alternativas competitivas para modelos com mais de duas vezes o seu tamanho. Este desempenho notável é alcançável em um único GPU Tensor Core NVIDIA H100 ou host TPU, reduzindo substancialmente os custos de implantação.
Um novo padrão em eficiência e desempenho de modelos de IA
Arquitetura redesenhada para desempenho ideal
Gemma 2 é construído em uma arquitetura redesenhada, projetada para oferecer desempenho excepcional e eficiência de inferência. Aqui estão alguns recursos principais que o destacam:
Desempenho descomunal
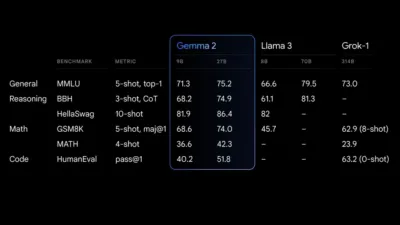
O modelo 27B Gemma 2 oferece o melhor desempenho da categoria para seu tamanho, oferecendo alternativas competitivas para modelos muito maiores. O modelo 9B Gemma 2 também se destaca, superando outros modelos abertos de sua categoria, como o Llama 3 8B. Para uma análise detalhada do seu desempenho, consulte o relatório técnico.
Apresentação final de Gemma 2
Eficiência e economia de custos incomparáveis
Projetado para inferência eficiente, o modelo 27B Gemma 2 opera com total precisão em um único host Google Cloud TPU, GPU NVIDIA A100 80GB Tensor Core ou GPU NVIDIA H100 Tensor Core. Esta eficiência não só garante um alto desempenho, mas também reduz significativamente os custos, tornando as implementações de IA mais acessíveis e económicas.
Inferência extremamente rápida em hardware
Gemma 2 é otimizado para velocidade incrível em várias configurações de hardware, desde poderosos laptops para jogos e desktops de última geração até ambientes baseados em nuvem. Você pode experimentar o Gemma 2 com total precisão no Google AI Studio, desbloquear o desempenho local com a versão quantizada usando Gemma.cpp em sua CPU ou executá-lo em seu computador doméstico com NVIDIA RTX ou GeForce RTX por meio de Hugging Face Transformers.
Abraçando o futuro da IA com Gemma 2
Impulsionando a inovação em IA globalmente
O lançamento do Gemma 2 representa um marco significativo para tornar as tecnologias avançadas de IA mais acessíveis a pesquisadores e desenvolvedores em todo o mundo. Ao fornecer modelos de alto desempenho que são eficientes e econômicos, o Gemma 2 capacita os inovadores a lidar com tarefas complexas de IA sem a barreira dos sistemas proprietários. Esta democratização das ferramentas de IA é crucial para promover a colaboração global e acelerar os avanços tecnológicos.
Compromisso com a Segurança e a IA Ética
Juntamente com as suas conquistas técnicas, o Gemma 2 incorpora melhorias substanciais de segurança para garantir a implantação ética da IA. Estes avanços sublinham o nosso compromisso em desenvolver tecnologias de IA que não só tenham um desempenho excecional, mas que também cumpram elevados padrões de segurança e responsabilidade.
Confira o outro Notícias sobre IA e eventos de tecnologia certos aqui no AIfuturize!