Google Gemma 2 發佈:為全球研究人員和開發人員賦能

Gemma 2:賦能全球人工智慧創新
傑瑪2簡介
人工智慧有潛力解決人類一些最迫切的挑戰,但這只有在每個人都能獲得利用它所需的工具的情況下才能實現。這就是為什麼,今年早些時候,我們推出了 Gemma,這是一個輕量級、最先進的開放模型系列,使用與 雙子座車型。從那時起,Gemma 系列已擴展到包括 CodeGemma、RecurrentGemma 和 PaliGemma,每個產品都為各種 AI 任務提供獨特的功能。透過與 Hugging Face、NVIDIA 和 Ollama 等合作夥伴集成,可以輕鬆存取這些模型。
Gemma 2 全球發布
我們很高興地宣布 Gemma 2 現已正式向全球研究人員和開發人員開放。 Gemma 2 提供 90 億 (9B) 和 270 億 (27B) 參數大小,在效能和效率方面都超越了第一代。憑藉顯著的安全進步,27B 型號為兩倍以上尺寸的型號提供了具有競爭力的替代品。這種非凡的性能可以在單一 NVIDIA H100 張量核心 GPU 或TPU主機,大幅降低部署成本。
AI 模型效率和性能的新標準
重新設計的架構以獲得最佳效能
Gemma 2 基於重新設計的架構構建,旨在提供卓越的性能和推理效率。以下是使其脫穎而出的一些關鍵功能:
超強性能
27B Gemma 2 型號在其尺寸中提供了同類最佳的性能,為更大型號提供了有競爭力的替代品。 9B Gemma 2 型號也表現出色,優於同類中的其他開放型號,例如 Llama 3 8B。有關其性能的詳細分類,請參閱技術報告。
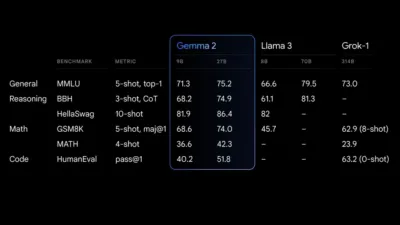
傑瑪2表演決賽
無與倫比的效率和成本節約
27B Gemma 2 型號專為高效推理而設計,可在單一 Google Cloud TPU 主機、NVIDIA A100 80GB Tensor Core GPU 或 NVIDIA H100 Tensor Core GPU 上以全精度運作。這種效率不僅確保了高效能,而且還顯著降低了成本,使人工智慧部署更容易實現且預算友好。
跨硬體的極速推理
Gemma 2 經過最佳化,可在各種硬體設定(從功能強大的遊戲筆記型電腦和高階桌上型電腦到基於雲端的環境)中實現令人難以置信的速度。您可以在 Google AI Studio 中全精度體驗 Gemma 2,使用 CPU 上的 Gemma.cpp 解鎖本地性能的量化版本,或者透過 Hugging Face Transformers 在配備 NVIDIA RTX 或 GeForce RTX 的家用電腦上運行它。
與 Gemma 2 一起擁抱人工智慧的未來
推動全球人工智慧創新
Gemma 2 的發布是讓全球研究人員和開發人員更容易使用先進人工智慧技術的一個重要里程碑。透過提供高效且經濟高效的高效能模型,Gemma 2 使創新者能夠擺脫專有系統的障礙來解決複雜的人工智慧任務。人工智慧工具的民主化對於促進全球協作和加速技術進步至關重要。
對安全和道德人工智慧的承諾
除了技術成就外,Gemma 2 還融入了大量的安全性增強功能,以確保符合道德的 AI 部署。這些進步凸顯了我們對建構人工智慧技術的承諾,這些技術不僅性能卓越,而且遵守高標準的安全和責任。
看看其他的 人工智慧新聞 和技術活動的權利 在 AIfuturize 中!