值得注意的是,這項突破性技術不僅可以識別腫瘤,還可以與使用者互動,為病理學的診斷和研究提供新的工具和視角。
PathChat:多模態病理檢測人工智慧助手
多年來,計算病理學在分析病理形態學數據和分子檢測數據方面取得了重大進展。這個由病理學與人工智慧和電腦視覺技術交叉形成的利基研究領域正逐漸成為醫學影像分析的研究熱點。
計算病理學涉及利用影像處理和人工智慧技術來建立人工智慧計算病理學模型。這些模型獲取組織病理學影像並對這些影像的形態學外觀進行初步評估,以透過自動影像分析技術協助診斷、定量評估和決策。
目前,隨著以ChatGPT為代表的生成式人工智慧技術的爆發式增長,多模態大語言模型(MLLM)越來越多地應用於計算病理學研究和病理臨床實踐。然而,在解剖病理學這一高度專業化的次領域,建構通用、多模式病理學人工智慧助理的研究仍處於早期階段。
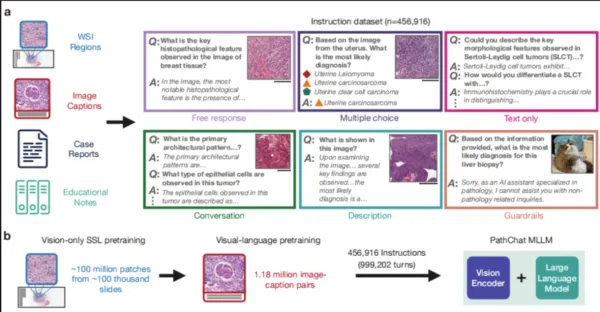
在這項工作中,研究團隊設計了一款專門用於人類病理學研究的多模態生成人工智慧助理——PathChat。他們透過自監督學習對來自超過 100 萬張載玻片的超過 1 億個細胞組織影像片段進行了預訓練。透過將其與最先進的純視覺編碼器 UNI 結合,他們產生了能夠推理視覺和自然語言輸入的 MLLM。經過對超過 450,000 個指令資料點的資料集進行微調後,建構了 PathChat。
研究發現,PathChat 不僅可以處理多模態輸入,還可以準確回應複雜的病理相關詢問,從近 90% 病例的活檢切片中正確識別疾病。
路徑路徑
超越 GPT-4V,精度接近 90%
為了測試 PathChat 的偵測效能,研究團隊將 PathChat 與開源模型 LLaVA、生物醫學專用的 LLaVA-Med 和 GPT-4V 進行了比較。
他們設計了 PathQABench 比較實驗,分析不同器官和實踐的病理病例,比較 PathChat 與 LLaVA、LLaVA-Med 和 GPT-4V 的檢測性能。
結果顯示,在不提供臨床背景的情況下,PathChat 的診斷準確性明顯高於 LLaVA 1.5 和 LLaVA-Med。僅評估影像時,PathChat 在所有組合基準測試中的準確度為 78.1%,比 LLaVA 1.5 高 52.4%,比 LLaVA-Med 高 63.8%。
隨著臨床背景的納入,PathChat 的準確率進一步提高至 89.5%,比 LLaVA 1.5 高出 39.0%,比 LLaVA-Med 高出 60.9%。
對比實驗表明,PathChat 可以僅從影像的視覺特徵中獲得大量的預測能力,而不是僅僅依賴臨床背景。它可以透過結合普通自然語言提供的非視覺訊息,有效、靈活地利用多模態資訊來準確診斷組織學圖像。
為了客觀評估每個模型對開放式問題回答的準確性,研究團隊招募了七位病理學家組成評估小組。透過比較四個模型對 260 個開放式問題的回答,分析了模型檢測的準確性。
最後,在七位專家能夠達成共識的開放式問題上,PathChat 的整體準確率為 78.7%,分別比 GPT-4V、LLaVA 1.5 和 LLaVA-Med 高出 26.4%、48.9% 和 48.1%。總體而言,與其他三個模型相比,PathChat 表現出了優越的性能。
研究人員表示,PathChat 可以分析和描述病理組織影像中微妙的形態細節。除了影像輸入之外,它還可以回答需要病理學和一般生物醫學背景知識的問題,使其成為協助病理學家和研究人員的有前途的工具。
儘管PathChat在實驗中表現出色,但在實際應用中仍面臨一些挑戰。其中包括確保模型能夠識別無效查詢並避免錯誤輸出,與最新的醫學知識保持同步,以及解決 PathChat 的訓練資料主要來自歷史資料的事實,這可能反映「過去的科學共識」而不是最新資訊。
研究人員表示,未來的研究可能會進一步增強 PathChat 的功能,包括支持整個十億像素 WSI 或多個 WSI 輸入,以及整合更多特定於任務的支持,例如精確計數或物件定位。此外,將 PathChat 與數位幻燈片檢視器或電子病歷整合可能會進一步提高其在臨床實踐中的實用性。
近日,多模態生成AI模型PathChat 2發布。它可以對病理圖像和文字進行推理,在互動式幻燈片檢視器中接受多個高解析度圖像和文字的交替輸入,從而為每個諮詢案例提供更全面的評估。
與PathChat 1相比,它在鑑別診斷和形態學描述方面的表現有顯著提升。它也增強了執行指令執行、開放式問答和報告摘要等任務的能力。