Lanzamiento de Google Gemma 2: empoderando a investigadores y desarrolladores de todo el mundo

Gemma 2: Potenciar la innovación global en IA
Introducción a Gema 2
La IA tiene el potencial de resolver algunos de los desafíos más apremiantes de la humanidad, pero esto sólo puede suceder si todos tienen acceso a las herramientas necesarias para aprovecharla. Es por eso que, a principios de este año, presentamos Gemma, una familia de modelos abiertos livianos y de última generación construidos utilizando la misma investigación y tecnología que el Modelos Géminis. Desde entonces, la familia Gemma se ha ampliado para incluir CodeGemma, RecurrentGemma y PaliGemma, cada uno de los cuales ofrece capacidades únicas para diversas tareas de IA. Se puede acceder fácilmente a estos modelos a través de integraciones con socios como Hugging Face, NVIDIA y Ollama.
Lanzamiento global de Gemma 2
Nos complace anunciar que Gemma 2 ya está oficialmente disponible para investigadores y desarrolladores de todo el mundo. Ofrecido en tamaños de parámetros de 9 mil millones (9B) y 27 mil millones (27B), Gemma 2 supera a la primera generación tanto en rendimiento como en eficiencia. Con importantes avances en seguridad, el modelo 27B ofrece alternativas competitivas a modelos de más del doble de su tamaño. Este extraordinario rendimiento se puede lograr con un solo GPU NVIDIA H100 con núcleo tensor o host de TPU, lo que reduce sustancialmente los costos de implementación.
Un nuevo estándar en eficiencia y rendimiento de los modelos de IA
Arquitectura rediseñada para un rendimiento óptimo
Gemma 2 se basa en una arquitectura rediseñada diseñada para ofrecer un rendimiento y una eficiencia de inferencia excepcionales. Estas son algunas de las características clave que lo hacen destacar:
Rendimiento descomunal
El modelo 27B Gemma 2 ofrece el mejor rendimiento de su clase para su tamaño y ofrece alternativas competitivas a modelos mucho más grandes. También destaca el modelo 9B Gemma 2, superando a otros modelos abiertos de su categoría, como el Llama 3 8B. Para un desglose detallado de su desempeño, consulte el informe técnico.
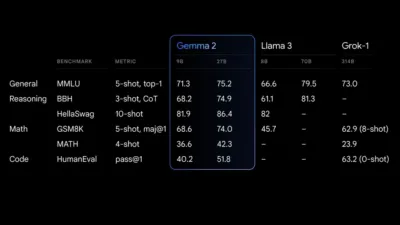
Final de actuación de Gemma 2
Eficiencia y ahorro de costos inigualables
Diseñado para una inferencia eficiente, el modelo 27B Gemma 2 opera con total precisión en un único host de TPU de Google Cloud, una GPU NVIDIA A100 de 80 GB Tensor Core o una GPU NVIDIA H100 Tensor Core. Esta eficiencia no solo garantiza un alto rendimiento sino que también reduce significativamente los costos, lo que hace que las implementaciones de IA sean más accesibles y económicas.
Inferencia increíblemente rápida a través del hardware
Gemma 2 está optimizado para una velocidad increíble en varias configuraciones de hardware, desde potentes portátiles para juegos y escritorios de alta gama hasta entornos basados en la nube. Puede experimentar Gemma 2 con total precisión en Google AI Studio, desbloquear el rendimiento local con la versión cuantificada usando Gemma.cpp en su CPU o ejecutarlo en la computadora de su hogar con una NVIDIA RTX o GeForce RTX a través de Hugging Face Transformers.
Abrazando el futuro de la IA con Gemma 2
Impulsando la innovación en IA a nivel mundial
El lanzamiento de Gemma 2 representa un hito importante para hacer que las tecnologías avanzadas de IA sean más accesibles para investigadores y desarrolladores de todo el mundo. Al proporcionar modelos de alto rendimiento que son eficientes y rentables, Gemma 2 permite a los innovadores abordar tareas complejas de IA sin la barrera de los sistemas propietarios. Esta democratización de las herramientas de IA es crucial para fomentar la colaboración global y acelerar los avances tecnológicos.
Compromiso con la seguridad y la IA ética
Además de sus logros técnicos, Gemma 2 incorpora importantes mejoras de seguridad para garantizar un despliegue ético de la IA. Estos avances subrayan nuestro compromiso de desarrollar tecnologías de IA que no solo funcionen de manera excepcional sino que también cumplan con altos estándares de seguridad y responsabilidad.
mira el otro noticias de IA y eventos tecnológicos correctos aquí en AIfuturize!