Rilasciato Google Gemma 2: maggiore potere a ricercatori e sviluppatori in tutto il mondo

Gemma 2: Potenziare l'innovazione globale dell'intelligenza artificiale
Introduzione a Gemma 2
L’intelligenza artificiale ha il potenziale per risolvere alcune delle sfide più urgenti dell’umanità, ma ciò può accadere solo se tutti hanno accesso agli strumenti necessari per sfruttarla. Ecco perché, all'inizio di quest'anno, abbiamo introdotto Gemma, una famiglia di modelli aperti leggeri e all'avanguardia, costruiti utilizzando la stessa ricerca e tecnologia del Modelli Gemelli. Da allora, la famiglia Gemma si è ampliata per includere CodeGemma, RecurrentGemma e PaliGemma, ciascuno dei quali offre funzionalità uniche per varie attività di intelligenza artificiale. Questi modelli sono facilmente accessibili attraverso integrazioni con partner come Hugging Face, NVIDIA e Ollama.
Rilascio globale di Gemma 2
Siamo entusiasti di annunciare che Gemma 2 è ora ufficialmente disponibile per ricercatori e sviluppatori di tutto il mondo. Offerto in dimensioni di parametri da 9 miliardi (9B) e 27 miliardi (27B), Gemma 2 supera la prima generazione sia in termini di prestazioni che di efficienza. Con significativi progressi in termini di sicurezza, il modello 27B offre alternative competitive a modelli di dimensioni più che doppie. Questa straordinaria prestazione è ottenibile su un singolo GPU NVIDIA H100 Tensor Core o host TPU, riducendo sostanzialmente i costi di implementazione.
Un nuovo standard nell'efficienza e nelle prestazioni dei modelli di intelligenza artificiale
Architettura riprogettata per prestazioni ottimali
Gemma 2 è costruito su un'architettura riprogettata progettata per offrire prestazioni eccezionali ed efficienza di inferenza. Ecco alcune caratteristiche chiave che lo distinguono:
Prestazioni fuori misura
Il modello 27B Gemma 2 offre le migliori prestazioni della categoria per le sue dimensioni, offrendo alternative competitive a modelli molto più grandi. Eccelle anche il modello 9B Gemma 2, surclassando altri modelli open della sua categoria, come il Llama 3 8B. Per un dettaglio dettagliato delle sue performance si rimanda alla relazione tecnica.
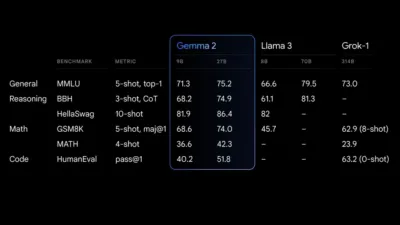
Finale di esibizione Gemma 2
Efficienza e risparmio sui costi senza pari
Progettato per un'inferenza efficiente, il modello 27B Gemma 2 funziona con la massima precisione su un singolo host Google Cloud TPU, GPU NVIDIA A100 Tensor Core da 80 GB o GPU NVIDIA H100 Tensor Core. Questa efficienza non solo garantisce prestazioni elevate, ma riduce anche significativamente i costi, rendendo le implementazioni dell’intelligenza artificiale più accessibili e convenienti.
Inferenza incredibilmente veloce attraverso l'hardware
Gemma 2 è ottimizzato per una velocità incredibile su varie configurazioni hardware, dai potenti laptop da gioco e desktop di fascia alta agli ambienti basati su cloud. Puoi sperimentare Gemma 2 con la massima precisione in Google AI Studio, sbloccare le prestazioni locali con la versione quantizzata utilizzando Gemma.cpp sulla tua CPU o eseguirlo sul tuo computer di casa con una NVIDIA RTX o GeForce RTX tramite Hugging Face Transformers.
Abbracciare il futuro dell'intelligenza artificiale con Gemma 2
Promuovere l’innovazione dell’intelligenza artificiale a livello globale
Il rilascio di Gemma 2 rappresenta una pietra miliare significativa nel rendere le tecnologie avanzate di intelligenza artificiale più accessibili a ricercatori e sviluppatori di tutto il mondo. Fornendo modelli ad alte prestazioni efficienti ed economici, Gemma 2 consente agli innovatori di affrontare compiti complessi di intelligenza artificiale senza la barriera dei sistemi proprietari. Questa democratizzazione degli strumenti di intelligenza artificiale è fondamentale per promuovere la collaborazione globale e accelerare i progressi tecnologici.
Impegno per la sicurezza e l'etica dell'intelligenza artificiale
Oltre ai risultati tecnici, Gemma 2 incorpora sostanziali miglioramenti in termini di sicurezza per garantire un’implementazione etica dell’IA. Questi progressi sottolineano il nostro impegno nella creazione di tecnologie di intelligenza artificiale che non solo funzionino in modo eccezionale, ma rispettino anche elevati standard di sicurezza e responsabilità.
Dai un'occhiata all'altro Novità sull'AI ed eventi tecnologici giusti qui in AIfuturize!