Google Gemma 2 đã được phát hành: Trao quyền cho các nhà nghiên cứu và nhà phát triển trên toàn thế giới

Gemma 2: Trao quyền cho sự đổi mới AI toàn cầu
Giới thiệu về Gemma 2
AI có tiềm năng giải quyết một số thách thức cấp bách nhất của nhân loại - nhưng điều này chỉ có thể xảy ra nếu mọi người đều có quyền truy cập vào các công cụ cần thiết để khai thác nó. Đó là lý do tại sao, đầu năm nay, chúng tôi đã giới thiệu Gemma, dòng sản phẩm mẫu mở nhẹ, hiện đại, được chế tạo bằng cách sử dụng nghiên cứu và công nghệ tương tự như Người mẫu Song Tử. Kể từ đó, dòng Gemma đã mở rộng để bao gồm CodeGemma, RecurrentGemma và PaliGemma, mỗi loại cung cấp các khả năng riêng biệt cho các nhiệm vụ AI khác nhau. Những mô hình này có thể dễ dàng truy cập thông qua việc tích hợp với các đối tác như Hugging Face, NVIDIA và Ollama.
Phát hành toàn cầu của Gemma 2
Chúng tôi vui mừng thông báo rằng Gemma 2 hiện đã chính thức có sẵn cho các nhà nghiên cứu và nhà phát triển trên toàn thế giới. Được cung cấp ở cả hai kích thước tham số 9 tỷ (9B) và 27 tỷ (27B), Gemma 2 vượt qua thế hệ đầu tiên cả về hiệu suất và hiệu quả. Với những tiến bộ đáng kể về an toàn, mẫu 27B cung cấp các lựa chọn thay thế cạnh tranh cho các mẫu có kích thước lớn hơn gấp đôi. Hiệu suất vượt trội này có thể đạt được chỉ bằng một GPU lõi Tensor NVIDIA H100 hoặc máy chủ TPU, giúp giảm đáng kể chi phí triển khai.
Tiêu chuẩn mới về hiệu quả và hiệu suất của mô hình AI
Kiến trúc được thiết kế lại để đạt hiệu suất tối ưu
Gemma 2 được xây dựng trên kiến trúc được thiết kế lại để mang lại hiệu suất và hiệu quả suy luận vượt trội. Dưới đây là một số tính năng chính làm cho nó nổi bật:
Hiệu suất vượt trội
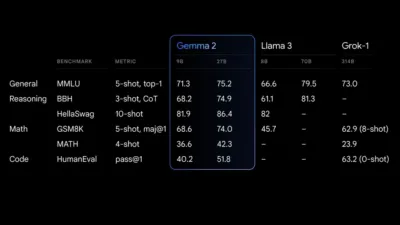
Mẫu 27B Gemma 2 mang lại hiệu suất tốt nhất so với kích thước của nó, cung cấp các lựa chọn thay thế cạnh tranh cho các mẫu lớn hơn nhiều. Mẫu 9B Gemma 2 cũng vượt trội, vượt trội so với các mẫu mở khác cùng loại, chẳng hạn như Llama 3 8B. Để biết chi tiết về hiệu suất của nó, hãy tham khảo báo cáo kỹ thuật.
Chung kết trình diễn Gemma 2
Hiệu quả và tiết kiệm chi phí chưa từng có
Được thiết kế để suy luận hiệu quả, mô hình 27B Gemma 2 hoạt động với độ chính xác tối đa trên một máy chủ Google Cloud TPU duy nhất, GPU NVIDIA A100 80GB Tensor Core hoặc GPU NVIDIA H100 Tensor Core. Hiệu quả này không chỉ đảm bảo hiệu suất cao mà còn giảm đáng kể chi phí, giúp việc triển khai AI trở nên dễ tiếp cận hơn và tiết kiệm ngân sách hơn.
Suy luận nhanh chóng trên phần cứng
Gemma 2 được tối ưu hóa để mang lại tốc độ đáng kinh ngạc trên nhiều thiết lập phần cứng khác nhau, từ máy tính xách tay chơi game mạnh mẽ và máy tính để bàn cao cấp cho đến môi trường dựa trên đám mây. Bạn có thể trải nghiệm Gemma 2 với độ chính xác hoàn toàn trong Google AI Studio, mở khóa hiệu suất cục bộ bằng phiên bản lượng tử hóa bằng Gemma.cpp trên CPU của bạn hoặc chạy nó trên máy tính ở nhà với NVIDIA RTX hoặc GeForce RTX thông qua Hugging Face Transformers.
Nắm bắt tương lai của AI với Gemma 2
Thúc đẩy đổi mới AI trên toàn cầu
Việc phát hành Gemma 2 đánh dấu một cột mốc quan trọng trong việc làm cho các công nghệ AI tiên tiến trở nên dễ tiếp cận hơn với các nhà nghiên cứu và nhà phát triển trên toàn cầu. Bằng cách cung cấp các mô hình hiệu suất cao, hiệu quả và tiết kiệm chi phí, Gemma 2 trao quyền cho các nhà đổi mới giải quyết các nhiệm vụ AI phức tạp mà không gặp rào cản từ các hệ thống độc quyền. Việc dân chủ hóa các công cụ AI này rất quan trọng để thúc đẩy sự hợp tác toàn cầu và thúc đẩy tiến bộ công nghệ.
Cam kết về an toàn và đạo đức AI
Bên cạnh những thành tựu kỹ thuật, Gemma 2 còn kết hợp những cải tiến đáng kể về an toàn để đảm bảo việc triển khai AI có đạo đức. Những tiến bộ này nhấn mạnh cam kết của chúng tôi trong việc xây dựng các công nghệ AI không chỉ hoạt động vượt trội mà còn tuân thủ các tiêu chuẩn cao về an toàn và trách nhiệm.
Kiểm tra cái khác tin tức AI và các sự kiện công nghệ phải không? ở đây trong AIfuturize!